返回
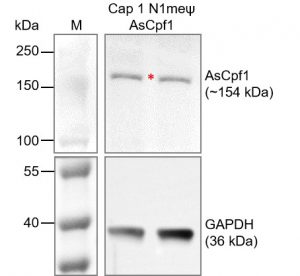
Cap 1 N1meψ AsCpf1 mRNA
AsCpf1 is a variant of the CRISPR-associated protein Cpf1, originating from Acidaminococcus sp. BV3L6. It was among the first Cpf1 orthologs identified and characterized, renowned for its efficiency and specificity in targeting DNA sequences. AsCpf1 is widely utilized in genome editing applications for its ability to induce precise genetic modifications by generating double-strand breaks at specific DNA sites. This mRNA possesses a Cap1 structure, which is highly efficient in capping. It is fully substituted with N1-methyl-pseudo Uridine to improve expression and decrease immunogenicity. Additionally, the mRNA features a 110A tail in its sequence, resembling a mature mRNA.
SKU: RNAP014
title
content
Gene name
AsCpf1
Function
Gene Editing tool
ORF sequence
ATGACACAGTTCGAGGGCTTTACCAACCTGTATCAGGTGAGCAAGACACTGCGGTTTGAGCTGATCCCACAGGGCAAGACCCTGAAGCACATCCAGGAGCAGGGCTTCATCGAGGAGGACAAGGCCCGCAATGATCACTACAAGGAGCTGAAGCCCATCATCGATCGGATCTACAAGACCTATGCCGACCAGTGCCTGCAGCTGGTGCAGCTGGATTGGGAGAACCTGAGCGCCGCCATCGACTCCTATAGAAAGGAGAAAACCGAGGAGACAAGGAACGCCCTGATCGAGGAGCAGGCCACATATCGCAATGCCATCCACGACTACTTCATCGGCCGGACAGACAACCTGACCGATGCCATCAATAAGAGACACGCCGAGATCTACAAGGGCCTGTTCAAGGCCGAGCTGTTTAATGGCAAGGTGCTGAAGCAGCTGGGCACCGTGACCACAACCGAGCACGAGAACGCCCTGCTGCGGAGCTTCGACAAGTTTACAACCTACTTCTCCGGCTTTTATGAGAACAGGAAGAACGTGTTCAGCGCCGAGGATATCAGCACAGCCATCCCACACCGCATCGTGCAGGACAACTTCCCCAAGTTTAAGGAGAATTGTCACATCTTCACACGCCTGATCACCGCCGTGCCCAGCCTGCGGGAGCACTTTGAGAACGTGAAGAAGGCCATCGGCATCTTCGTGAGCACCTCCATCGAGGAGGTGTTTTCCTTCCCTTTTTATAACCAGCTGCTGACACAGACCCAGATCGACCTGTATAACCAGCTGCTGGGAGGAATCTCTCGGGAGGCAGGCACCGAGAAGATCAAGGGCCTGAACGAGGTGCTGAATCTGGCCATCCAGAAGAATGATGAGACAGCCCACATCATCGCCTCCCTGCCACACAGATTCATCCCCCTGTTTAAGCAGATCCTGTCCGATAGGAACACCCTGTCTTTCATCCTGGAGGAGTTTAAGAGCGACGAGGAAGTGATCCAGTCCTTCTGCAAGTACAAGACACTGCTGAGAAACGAGAACGTGCTGGAGACAGCCGAGGCCCTGTTTAACGAGCTGAACAGCATCGACCTGACACACATCTTCATCAGCCACAAGAAGCTGGAGACAATCAGCAGCGCCCTGTGCGACCACTGGGATACACTGAGGAATGCCCTGTATGAGCGGAGAATCTCCGAGCTGACAGGCAAGATCACCAAGTCTGCCAAGGAGAAGGTGCAGCGCAGCCTGAAGCACGAGGATATCAACCTGCAGGAGATCATCTCTGCCGCAGGCAAGGAGCTGAGCGAGGCCTTCAAGCAGAAAACCAGCGAGATCCTGTCCCACGCACACGCCGCCCTGGATCAGCCACTGCCTACAACCCTGAAGAAGCAGGAGGAGAAGGAGATCCTGAAGTCTCAGCTGGACAGCCTGCTGGGCCTGTACCACCTGCTGGACTGGTTTGCCGTGGATGAGTCCAACGAGGTGGACCCCGAGTTCTCTGCCCGGCTGACCGGCATCAAGCTGGAGATGGAGCCTTCTCTGAGCTTCTACAACAAGGCCAGAAATTATGCCACCAAGAAGCCCTACTCCGTGGAGAAGTTCAAGCTGAACTTTCAGATGCCTACACTGGCCTCTGGCTGGGACGTGAATAAGGAGAAGAACAATGGCGCCATCCTGTTTGTGAAGAACGGCCTGTACTATCTGGGCATCATGCCAAAGCAGAAGGGCAGGTATAAGGCCCTGAGCTTCGAGCCCACAGAGAAAACCAGCGAGGGCTTTGATAAGATGTACTATGACTACTTCCCTGATGCCGCCAAGATGATCCCAAAGTGCAGCACCCAGCTGAAGGCCGTGACAGCCCACTTTCAGACCCACACAACCCCCATCCTGCTGTCCAACAATTTCATCGAGCCTCTGGAGATCACAAAGGAGATCTACGACCTGAACAATCCTGAGAAGGAGCCAAAGAAGTTTCAGACAGCCTACGCCAAGAAAACCGGCGACCAGAAGGGCTACAGAGAGGCCCTGTGCAAGTGGATCGACTTCACAAGGGATTTTCTGTCCAAGTATACCAAGACAACCTCTATCGATCTGTCTAGCCTGCGGCCATCCTCTCAGTATAAGGACCTGGGCGAGTACTATGCCGAGCTGAATCCCCTGCTGTACCACATCAGCTTCCAGAGAATCGCCGAGAAGGAGATCATGGATGCCGTGGAGACAGGCAAGCTGTACCTGTTCCAGATCTATAACAAGGACTTTGCCAAGGGCCACCACGGCAAGCCTAATCTGCACACACTGTATTGGACCGGCCTGTTTTCTCCAGAGAACCTGGCCAAGACAAGCATCAAGCTGAATGGCCAGGCCGAGCTGTTCTACCGCCCTAAGTCCAGGATGAAGAGGATGGCACACCGGCTGGGAGAGAAGATGCTGAACAAGAAGCTGAAGGATCAGAAAACCCCAATCCCCGACACCCTGTACCAGGAGCTGTACGACTATGTGAATCACAGACTGTCCCACGACCTGTCTGATGAGGCCAGGGCCCTGCTGCCCAACGTGATCACCAAGGAGGTGTCTCACGAGATCATCAAGGATAGGCGCTTTACCAGCGACAAGTTCTTTTTCCACGTGCCTATCACACTGAACTATCAGGCCGCCAATTCCCCATCTAAGTTCAACCAGAGGGTGAATGCCTACCTGAAGGAGCACCCCGAGACACCTATCATCGGCATCGATCGGGGCGAGAGAAACCTGATCTATATCACAGTGATCGACTCCACCGGCAAGATCCTGGAGCAGCGGAGCCTGAACACCATCCAGCAGTTTGATTACCAGAAGAAGCTGGACAACAGGGAGAAGGAGAGGGTGGCAGCAAGGCAGGCCTGGTCTGTGGTGGGCACAATCAAGGATCTGAAGCAGGGCTATCTGAGCCAGGTCATCCACGAGATCGTGGACCTGATGATCCACTACCAGGCCGTGGTGGTGCTGGAGAACCTGAATTTCGGCTTTAAGAGCAAGAGGACCGGCATCGCCGAGAAGGCCGTGTACCAGCAGTTCGAGAAGATGCTGATCGATAAGCTGAATTGCCTGGTGCTGAAGGACTATCCAGCAGAGAAAGTGGGAGGCGTGCTGAACCCATACCAGCTGACAGACCAGTTCACCTCCTTTGCCAAGATGGGCACCCAGTCTGGCTTCCTGTTTTACGTGCCTGCCCCATATACATCTAAGATCGATCCCCTGACCGGCTTCGTGGACCCCTTCGTGTGGAAAACCATCAAGAATCACGAGAGCCGCAAGCACTTCCTGGAGGGCTTCGACTTTCTGCACTACGACGTGAAAACCGGCGACTTCATCCTGCACTTTAAGATGAACAGAAATCTGTCCTTCCAGAGGGGCCTGCCCGGCTTTATGCCTGCATGGGATATCGTGTTCGAGAAGAACGAGACACAGTTTGACGCCAAGGGCACCCCTTTCATCGCCGGCAAGAGAATCGTGCCAGTGATCGAGAATCACAGATTCACCGGCAGATACCGGGACCTGTATCCTGCCAACGAGCTGATCGCCCTGCTGGAGGAGAAGGGCATCGTGTTCAGGGATGGCTCCAACATCCTGCCAAAGCTGCTGGAGAATGACGATTCTCACGCCATCGACACCATGGTGGCCCTGATCCGCAGCGTGCTGCAGATGCGGAACTCCAATGCCGCCACAGGCGAGGACTATATCAACAGCCCCGTGCGCGATCTGAATGGCGTGTGCTTCGACTCCCGGTTTCAGAACCCAGAGTGGCCCATGGACGCCGATGCCAATGGCGCCTACCACATCGCCCTGAAGGGCCAGCTGCTGCTGAATCACCTGAAGGAGAGCAAGGATCTGAAGCTGCAGAACGGCATCTCCAATCAGGACTGGCTGGCCTACATCCAGGAGCTGCGCAACAAAAGGCCGGCGGCCACGAAAAAGGCCGGCCAGGCAAAAAAGAAAAAGGGATCCTACCCATACGATGTTCCAGATTACGCTTAA
Species
Synthetic
Cellular localization of the protein
N-terminal and C-terminal NLS
Reference/PubMed link
https://www.ncbi.nlm.nih.gov/pubmed/34948095
Concentration
1mg/mL
Storage Buffer
Rnase Free H2O
Gene length (bp)
4005
Molecular Weight (kDa)
1450.4
Storage Temperature
-80°C
Shipping Condition
Dry ice
Appearance
Clear and colorless
Purity
Fragment analysis by capillary electrophoresis
Base Composition
N1meψ
Capping
Cap1
Tag
N-HA
Stock
On-demand